Agent Reasoning
- Your agent reasons through problems by gathering context, selecting tools, and iterating until it has answers
- Three context sources feed reasoning: connectors (data), knowledge and memory (experience), and workspace tools (code access)
- New agents bootstrap context through an onboarding analysis of your connected repositories
- The agent remembers what it learns — tell it facts in natural conversation and it stores them as persistent memory
- The reasoning loop runs up to 10 times per turn, adapting depth to problem complexity
Your agent reasons through problems rather than following scripts. It draws on three sources of context — connected data, persistent knowledge, and direct code access — to reason about your systems, not generic ones. It gathers evidence, selects the right tools, classifies actions by risk, and explains its thinking — all visible in the chat interface.
What your agent knows
Your agent's reasoning quality depends on the context it can access. Three sources feed into every investigation:
| Context source | What it provides | How to add it |
|---|---|---|
| Connectors | Live data from GitHub, Azure DevOps, Kusto, Azure Monitor, and other services | Connectors → |
| Knowledge and memory | Uploaded runbooks, architecture docs, and facts from past conversations | Memory & Knowledge → |
| Workspace tools | Direct access to read, search, and analyze your source code, run terminal commands, and execute Python | Connect a repository → |
The more context you provide, the better your agent reasons. An agent with connected repos, uploaded runbooks, and several conversations under its belt reasons fundamentally differently from one that was just created — it knows where your retry logic lives, what your team's escalation path is, and what worked last time this type of issue happened.
Bootstrapping your agent's context
When you first set up your agent and connect a repository, the agent immediately starts building understanding of your environment:
- Explores your codebase — reads project structure, technology stack, deployment configurations, and service dependencies
- Creates knowledge files — produces architecture documentation and team context files based on what it discovers
- Opens a PR — creates an
SREAGENT.mdfile summarizing its understanding for your team to review and merge - Conducts an onboarding interview — asks about your team structure, escalation paths, and operational procedures in an interactive conversation
After onboarding, your agent knows how your services connect, what your deployment configurations look like, and what your team's procedures are — before you ask your first investigation question.
→ Complete the team onboarding experience
Persistent memory
Your agent remembers what it learns across conversations. After each session, it extracts key findings — resolution steps, root causes, environment facts — and stores them as persistent memory.
You can tell your agent facts directly in natural conversation:
"Remember that our Redis cache uses Premium tier with 6GB"
"Keep in mind our escalation path is PagerDuty → Teams channel → phone"
"Our deployment window is Tuesdays 2–4pm Pacific"
The agent stores these as persistent memory and recalls them automatically in future conversations when they're relevant.
Your team can also upload knowledge documents — runbooks, architecture guides, team procedures — that the agent references at the start of every conversation.
The reasoning loop
Every message you send goes through the same loop:

The agent first understands your request and identifies what data is needed. Then it gathers context — querying data sources in parallel (logs, metrics, resource status, deployment history, memory). Next it reasons over gathered data, identifying patterns and forming conclusions. Finally it acts or responds — executing safe actions, requesting approval for risky ones, or presenting findings.
If the problem requires more work, the loop iterates — up to 10 times per turn. After that, your agent asks whether to continue.
Your agent uses multiple AI models internally, automatically selecting the best one for each task based on factors like reasoning depth, speed, and input size. You don't select or configure models per conversation — model selection is managed at the agent level.
Adaptive thinking
For complex problems, your agent shows its reasoning process in the chat. A collapsible Thinking section appears with descriptive titles for each step — like "Exploring Azure health issues" or "Analyzing active alerts" — and elapsed time:
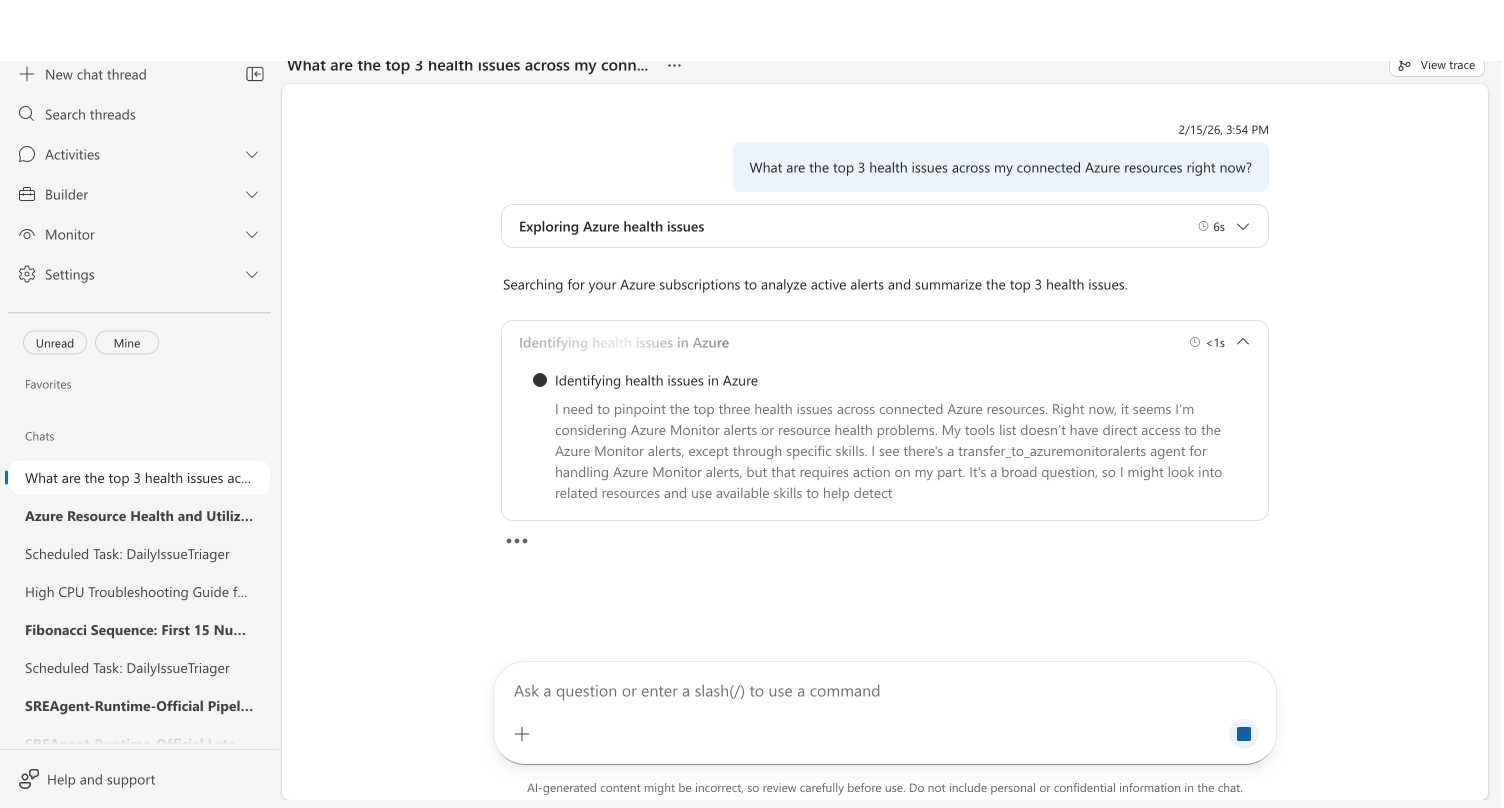
Your agent adjusts reasoning depth automatically. A status check gets a quick response. A multi-service outage gets multi-step reasoning with evidence correlation.
Tool selection
Your agent selects tools strategically based on the problem. It starts with all tools registered on the current custom agent, then filters by platform — using only incident tools for the connected incident platform. It further filters by published list to include only tools you've made available, and adjusts as new information emerges during the conversation.
Each custom agent has its own tool set. When your agent delegates to a different custom agent, the available tools change automatically.
For more on what tools are available, see Tools.
Parallel execution
When your agent identifies independent operations — actions that do not depend on each other's output — it issues them simultaneously in a single turn rather than running them one at a time.
For example, if your agent needs to check pod status, service health, and deployment history, it runs all three commands in parallel instead of waiting for each one to complete before starting the next. This reduces the number of reasoning turns and speeds up investigations.
Web search (Claude models)
Anthropic Claude models require opt-in and are not available to all tenants. Organizations with EU data residency requirements should review the data residency considerations — Anthropic is excluded from EUDB commitments.
When your agent uses Anthropic Claude as its default model provider, web search is automatically available. The agent can search the web during investigations to find documentation, error explanations, and troubleshooting guides — no configuration required.
Web search results appear as collapsible tool cards in the conversation, just like any other tool invocation. The agent autonomously decides when web search would be helpful based on the conversation context.
Action classification
Your agent classifies every action before executing:
| Classification | Behavior | Examples |
|---|---|---|
| Safe | Executes immediately | Query logs, check resource status, list deployments |
| Cautious | Executes with a brief explanation | Send emails, post Teams messages |
| Destructive | Requires your confirmation | Restart an app, scale resources, modify configurations |
How your agent handles each type depends on your run mode:
| Run mode | Safe | Cautious | Destructive |
|---|---|---|---|
| Review | Executes | Executes | Asks for approval |
| Autonomous | Executes | Executes | Executes |
Conversation management
Several mechanisms keep long conversations productive:
| Mechanism | What it does |
|---|---|
| Compaction | When conversations get very long, your agent summarizes earlier context while preserving key findings. You can trigger this manually with the /compact command. |
| Automatic retries | If a service interruption occurs mid-response, your agent retries transparently. |
| Error handling | If a model encounters a temporary issue, your agent displays a user-friendly message ("model is temporarily experiencing issues") instead of a generic internal error. |
Cancellation
When you click Stop, your agent immediately halts all operations and prevents retrying the cancelled task. Your next message starts fresh — unless you explicitly modify the cancelled request.
Boundaries
| What reasoning does | What it does not do |
|---|---|
| Gathers evidence from multiple sources in parallel | Guarantee finding a root cause — evidence may be insufficient |
| Classifies actions and respects your run mode | Auto-remediate without confirmation in Review mode |
| Explains its thinking step by step | Share investigation methodology across separate agents |
| Adjusts reasoning depth to problem complexity | Replace human judgment for critical decisions |
Related
| Topic | What it covers |
|---|---|
| Root Cause Analysis → | Deep investigation with hypothesis trees |
| Connectors → | Connect data sources to feed your agent's context |
| Memory & Knowledge → | How your agent remembers and references your documentation |
| Run Modes → | Review and Autonomous behavior |
| Tools → | Built-in and custom tool capabilities |
| Skills → | Domain-specific investigation procedures |
Next steps
| Resource | Why it matters |
|---|---|
| Connect a GitHub repository | Give your agent access to your source code |
| Complete team onboarding | Bootstrap your agent's understanding of your environment |
| Run your first investigation | See reasoning in action |